Participating in the Airbyte x Hashnode Hackathon: My Story

Hey👋, It's me Utsav, I craft code and love to write what I learn.
Overview
Just 30 days ago, I was introduced to the dynamic collaboration between Airbyte and Hashnode. This hackathon stood out from the typical ones organized by Hashnode over the years. Unlike the conventional hackathons focused on building products with specific tech stacks, this unique event aligned perfectly with Hacktoberfest. It was all about enhancing connectors and crafting quickstart guides for Airbyte, with participants contributing through pull requests.
About Airbyte
Airbyte, a leading open-source data integration platform, excels in effortlessly syncing data from diverse sources (APIs, databases, files) to chosen destinations like data warehouses and lakes. It stands out with 350+ connectors and a robust community focus. Notably, its extensibility offers versatile data integration solutions.
💡Know more: Click here
Tools I use
In the hackathon, I felt confident in my ability to create effective quickstart guides, and to address the unique challenges that came my way, I made use of a range of tools:
1. Terraform
Terraform is a versatile infrastructure as code (IaC) tool that automates the provisioning and management of cloud resources, offering simplicity and flexibility in infrastructure management.
2. BigQuery
BigQuery is Google Cloud's serverless data warehouse and analytics platform, ideal for handling large-scale data analysis. It offers fast query performance, scalability, and seamless integration with other Google Cloud services, making it a valuable tool for data-driven insights and decision-making.
3. Dbt
dbt (data build tool) is a transformative data transformation and modeling tool. It helps data professionals easily transform and structure data for analytics, making it ready for querying in databases.
My contribution
In the hackathon, I dedicated my efforts to quickstart development, resulting in two valuable contributions:
GitHub Insights Stack (Merged)
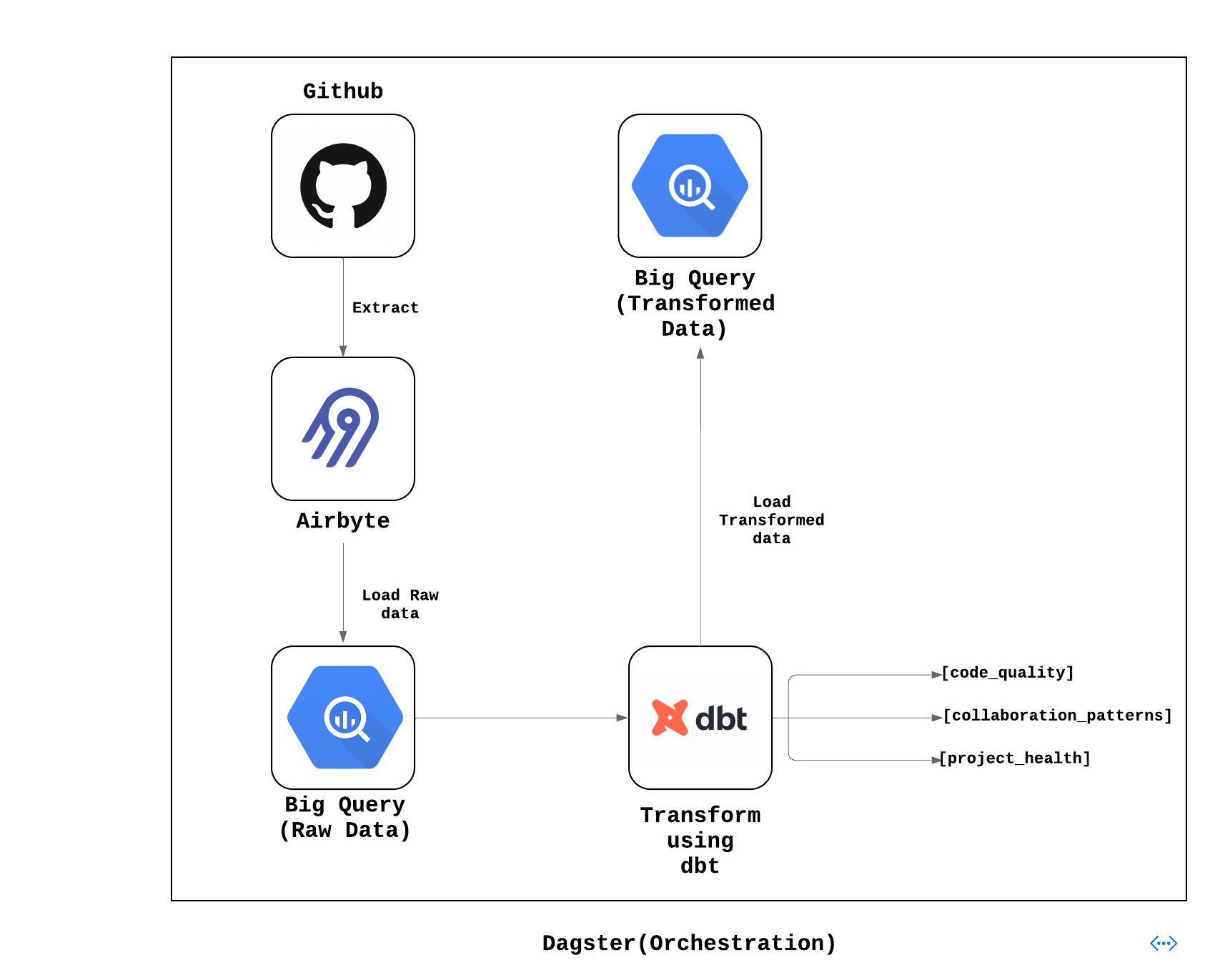
This quickstart offers a seamless setup for a data stack using Airbyte, dbt, and the GitHub API. It allows you to extract the GitHub repository, commit, and pull request data, perform transformations, and gain insights into code quality, collaboration, and project health.
💡Learn more: Click here
Performance Optimization Stack (In Progress)
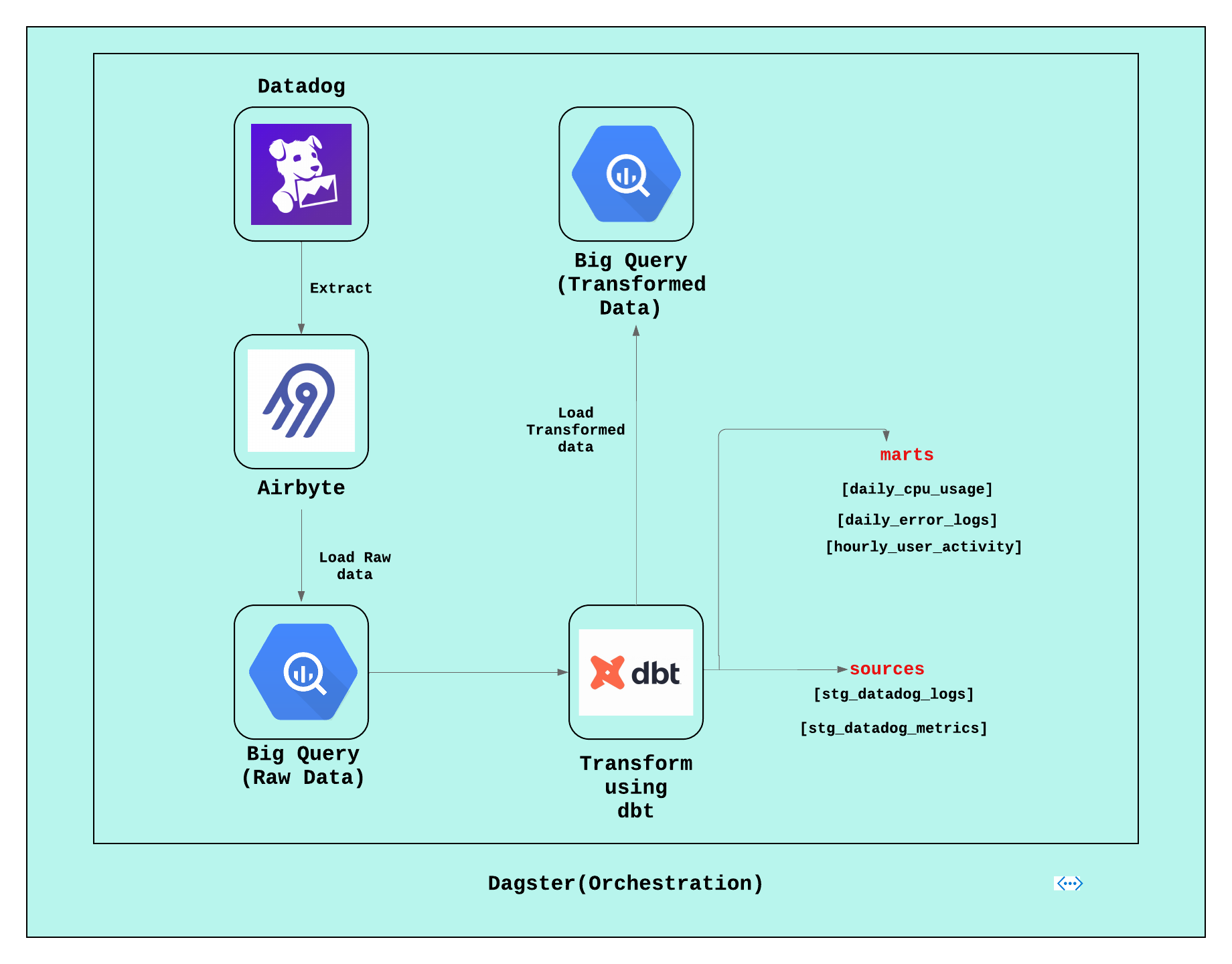
While this quickstart isn't complete due to limitations with Airbyte and Datadog integration, it aims to guide users through setting up smooth data integration between Datadog, Airbyte, and dbt. The goal is to extract performance metrics and logs from Datadog with Airbyte, then use dbt to transform and analyze the data for optimizing system performance and resource utilization.
💡Learn more: Click here (pull request)
Challenges
Learning Curve: When I started in data engineering, I had to begin from scratch, which was tough. To overcome this, I spent time learning and practicing, gradually building my knowledge.
Problem-Solving: Making the quickstarts required solving problems. I did this by taking a step-by-step approach, asking for help when needed, and using what I'd learned.
Time Constraints: The hackathon had time limits, and I was still learning. To manage this, I learned how to use my time wisely, focus on important tasks, and use available resources effectively.
Integration Limitations: While working on the second quickstart, I faced issues with connecting Airbyte and Datadog. Sadly, I won't be able to complete it due to my exam and time limitation.
Conclusion
In conclusion, my journey as a beginner in data engineering was a path filled with challenges that I actively embraced and overcame. These experiences reflect my dedication to learning and my ability to tackle obstacles in the ever-evolving field of data engineering.




